
Why Cars Drive Themselves Before Computers Do
Robocars are ready; robot secretaries aren’t… yet.

Waymo has already given 10 million fully driver-free rides (May 2025). Tesla owners have racked up ~3.6 billion miles on FSD (Full Self Driving). Yet no AI agent can book a round-trip flight without you hovering over its shoulder. This feels backward. Steering a 5,000-lb car through heavy traffic feels much harder than clicking buttons on a website. So, why is digital autonomy behind?
Both systems rest on the same four-layer autonomy stack: Perception → Reasoning → Action → Data Flywheel. The basic plumbing at the “Action” layer is the biggest hold-up for AI agents today. Cars have a simpler “Action” step: throttle, brake, steer, on roads whose rules rarely change. Agents have vastly more complexity. Their 'Action' layer operates in a fast-changing digital environment with orders-of-magnitude more degrees of freedom: where to click, what to type, what tools to use. Meanwhile, they must manage brittle APIs, authentication scopes, and data privacy challenges.
I predict this world order will flip. Why? First, the data flywheels for AI agents are much faster, cheaper, better than cars. The cost of error can be fatal with cars. This data flywheel will lead to compounding advantages in other parts of the stack. Second, AI agents just got much better plumbing with a standard protocol like MCP that helps agents collaborate. This significantly improved the “Action” layer and together with a strong data flywheel puts AI agents on a much steeper improvement curve.
We’re living in a brief moment where robots roam the streets while desktop bots are tethered to human intervention but that balance won’t last. Prediction: AI agents will reach mass adoption way before Autonomous Vehicles do. More precisely, I predict that a personal AI secretary will clear a 100M paid user mark years before a 100M users ride a Level-4 autonomous vehicle.

To understand why this reversal will happen, we need to break down what makes any autonomous system work. Both self-driving cars and AI agents share the same fundamental architecture, but they perform very differently on each component. In this article I dive deeper into:
The principal components of autonomy
Deep dive into AI Agents
Takeaways for builders and investors
Part 1 Principal components of autonomy
Under the hood, every autonomous stack can be broken down into four fundamental layers: Perception → Reasoning → Action → Data Flywheel.
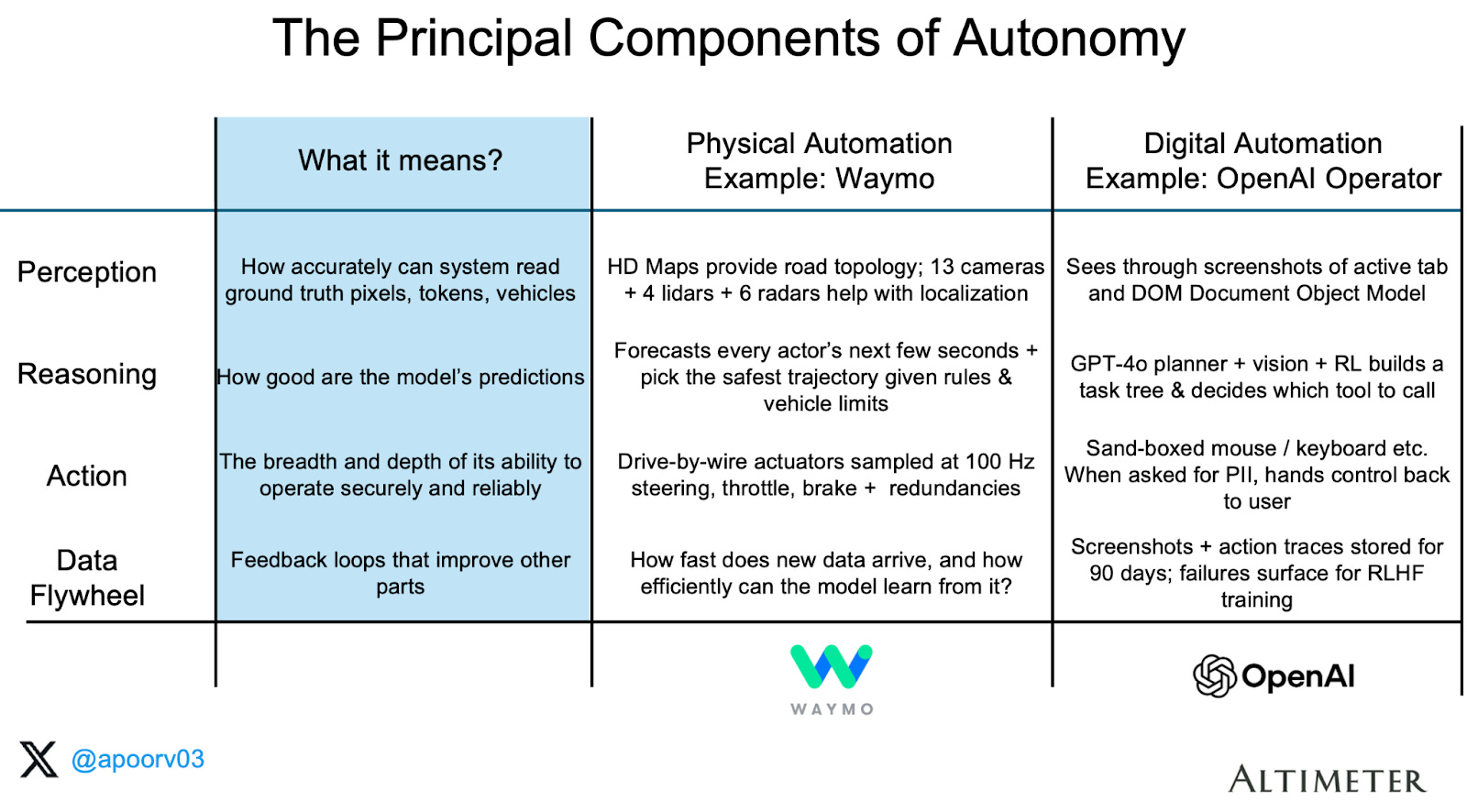
The autonomous systems share some attributes in common (e.g. the Transformer architecture turbo-charged the Reasoning layer for both physical and digital world), their performance on these four layers is quite varying. For instance, the promise of humanoid robots was re-ignited with the ChatGPT launch. However I suspect that they are both farther behind and slower in getting to L4-equivalent autonomy. For two main reasons: 1) lack of large diversified data for pretraining and 2) data flywheel is quite slow / expensive for post training improvements as well. With this framework in mind, I evaluate how different autonomous systems stack up across these four layers:

Data flywheel is emerging as a key variable. It compounds with implicit and explicit human feedback - essentially anything that can provide ground truth for the model to improve its behavior. For instance, this is how a toddler learns to walk via reinforcement learning. Falling is failure :) The fall reinforces to the toddler “don’t fall”. Similarly, OpenAI's products have a massive audience of 500m Weekly Active Users (WAUs) providing feedback at billions of feedback points per day. This has been the secret of why OpenAI products are improving fast and are likable. This is not too dissimilar from other versions of Reinforcement Learning (RL) we have seen in consumer products before.
On X/Twitter overdoing targeting makes content feel like “clickbait”. Similarly, overdoing RL in ChatGPT feels like sycophancy! In the case of self-driving cars, the feedback does exist but is less frequent, harder to integrate and more expensive.
This framework reveals why cars currently lead the autonomy race but it also shows why that lead won't last. The data flywheel advantage that AI agents possess is just beginning to compound. To see how this plays out, let's examine digital autonomy in detail and trace its rapid evolution.
Part 2 Deep dive into digital autonomy (AI Agents)
Software agents have leapt from “chatbots that answer” to “co-workers that do.” Unlike embodied robots, they benefit from (1) cheap, abundant feedback loops and (2) instant distribution over the Web, letting them learn orders-of-magnitude faster than their hardware cousins. Digital agents can see and think incredibly well, and they get smarter with every user interaction. However, they still struggle to do things on our behalf with the consistency, safety, and speed that real-world workflows demand. Closing that last mile is the biggest remaining unlock.
Where are we today? The table below benchmarks today’s best-known agent classes on the four autonomy pillars:

This snapshot shows digital agents' current strengths and weaknesses, but the picture is changing fast. Three major trends are reshaping the landscape
#1 From single agent to swarms of agents: In just twenty-four months we’ve watched digital agents sprint through three waves: (1) single-turn chatbots that only answer questions, (2) single-agent “copilots” that can decide what sub-steps to run like code-gen, SQL, classification, etc. (case in point: GitHub Copilot has ~15 million users who let the tool auto-write “46 % of their code” ) and now (3) multi-agent “crews” and agentic workflows that delegate tasks among specialised workers (planner, researcher, executor, evaluator). Frameworks like crewAI, AutoGen and LangGraph have made it trivial to spin up these swarms, turning what used to be brittle prompt-chaining into reusable, event-driven microservices.
#2 “Action” is the brittle tier of the stack but a few great efforts to improve it such as MCP: Model Context Protocol (MCP) is like a USB-C that joins Reasoning to Action. It standardised how agents talk to external tools and data. Instead of bespoke wrappers for GitHub, Slack or a private DB, a Host agent sends an MCP request to a lightweight Server that owns auth, auditing and schema versioning. The Server returns a prompt-ready response the model can reason over, then loops back when the model issues the next call. By moving the “what credential, what endpoint, what retry” logic out of the prompt and into the protocol, MCP lets the reasoning layer plan confidently while the action layer executes safely and deterministically. The prize: agents that improve with every feedback datapoint and ship real transactions without humans hovering over the “Undo” button. MCP has tradeoffs—ultimately, we're trading flexibility for cost. A MCP call is more expensive than an API call.
#3 Identity is another key part of the agentic stack that needs to mature. The moment an agent graduates from read-only to write access, it inherits all the messy realities of enterprise auth. Each API call must run under the right SSO session, respect per-object ACLs, and leave an audit trail. A single over-broad token can leak customer data or nuke a prod table. A few great efforts in the space are 1) Descope (offers drag-and-drop authentication management workflows so agents can borrow a user’s identity without developers hand-rolling OAuth flows) and 2) Arcade.dev (provides pre-authenticated “tool-calling” connectors that let LLMs act on Gmail, Calendars, or internal APIs while keeping scopes tight and revocable)
Part 3 Takeaways for builders & investors
Autonomous systems win by improving on the slowest link in a four-layer chain (Perception → Reasoning → Action → Flywheel). Transformers solved “good-enough” reasoning for most tasks; now the race is about plumbing reliable inputs, executing deterministically, and compounding data faster than peers. Here are a few best practices I picked up surveying practitioners:
Figure out the bottleneck by auditing each layer separately. A flashy demo often masks a weak action layer (PC agents) or a constrained flywheel (HD-map AVs). Transformers aren’t the end of the story. Reasoning is solved enough for most use-cases; returns now come from better perception (plumbing to connectors, sensors), precise action or faster flywheels (data rights, edge deployment).
For instance, in humanoid robotics the biggest bottleneck is access to diversified data at scale for pre-training (Perception)!
In customer service agents, the biggest bottleneck right now is instruction following while minimizing latency (Perception <> Action). In a few months, hopefully that bottleneck is something different.
In the case of Waymo you can see the evolution of Waymo’s performance and the gains were driven by different parts of the stack at different times. See chart:

How to read this data:
Big drop 2015-20 – steady software & sensor gains on easier suburban routes.
Spike in 2021 – most CA testing shifted to dense San Francisco; tougher edge-cases meant safety drivers intervened more often.
Recovery 2022-23 – model, policy & mapping updates pushed rates back down.
‘24 uptick – fleet scaled 4x and Waymo mixed commercial robotaxi duty with drivered test miles; test miles skew toward the hardest, still-unsolved scenarios.
Find ways to accelerate the Flywheel! Capture explicit and implicit user feedback from day one; automate labeling and retraining to shorten the loop and drive marginal-cost-efficient quality gains. A few examples:
Glean learns an incredible amount of user activity that helps improve personalization but also gathers post training data.
In voice customer service, where instruction following in live audio is tough, creating data on what tool calls are not working with precision (e.g. call routing, reservations, cancellations etc.), with real world examples (even if anonymized with masked PII) can be valuable. This creates valuable post-training data that can help improve underlying model performance.
Embed auto-evaluations. Stand up an automated eval harness that 1) houses deterministic task suites, 2) executes every new model/agent build (CI-style), and 3) blocks deployment while surfacing granular traces. A few real-life examples include Zapier (they block PRs that fail tool-call and task-success checks) and Airtable (their AI Assistant streams all prompt logs to Braintrust, tags failures, and retrains prompts/models only after the test suite is green).
Harden execution & security. Adopt structured tool-calling (MCP is the leading protocol), least-privilege tokens (not doing so could create tough times), and replayable audit logs. Target a minimum task success rate before scaling to customers.
Thanks to Alexander Matthey, Sud Bhatija, Jamie Beaton, Cobi Gantz, Sahil Aggarwal, Axel Dittman, Angad Singh, Matt Elkherj, and Will McCarthy for their feedback on this article.
The information presented in this newsletter is the opinion of the author and does not necessarily reflect the view of any other person or entity, including Altimeter Capital Management, LP ("Altimeter"). The information provided is believed to be from reliable sources but no liability is accepted for any inaccuracies. This is for information purposes and should not be construed as an investment recommendation. Past performance is no guarantee of future performance. Altimeter is an investment adviser registered with the U.S. Securities and Exchange Commission. Registration does not imply a certain level of skill or training. Altimeter and its clients trade in public securities and have made and/or may make investments in or investment decisions relating to the companies referenced herein. The views expressed herein are those of the author and not of Altimeter or its clients, which reserve the right to make investment decisions or engage in trading activity that would be (or could be construed as) consistent and/or inconsistent with the views expressed herein.
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on, the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update the information or analysis contained herein in the future.
The levels framework returns: https://blog.palantir.com/levels-9be772098942
Really sharp take—this article nails why execution, not reasoning, is the real unlock for AI agents. With MCP and rapid feedback loops, the autonomy race might flip faster than most expect. Thanks for sharing your insights!