
Deep Learning 101
This is meant to be a quick (under 10 min) read for a non-technical audience. Enjoy!

This is meant to be a quick (under 10 min) read for a non-technical audience. Enjoy!
The Problem
BLUF (Bottom Line Upfront): The goal/problem/mission is to recreate the human intelligence at a machine level (Artificial Intelligence). Breaks down to broadly three atomic steps Receive input → Understand → Act.
Step 1: Receive inputs (video, images, sound, text and soon hopefully olfactory data too)
Step 2: Understand (humans use different parts of the brain to process different sensory signal, machines use various custom architected GPUs/supercomputers optimized to solve specific problems (vision or speech or text))
Step 3: Act (drive a car based on road conditions).
Why is that hard? Consider a simple problem — someone across the room throws a ball at you and you catch it. Sounds simple, but actually, this is one of the most complex processes we’ve ever attempted to comprehend — let alone recreate at a machine level. What actually happens in the human circuitry is: the image of the ball passes through your eye and strikes your retina, which does some elementary analysis and sends it along to the brain, where the visual cortex more thoroughly analyzes the image. It then sends it out to the rest of the cortex, which compares it to everything it already knows, classifies the objects and dimensions, and finally decides on something to do: raise your hand and catch the ball (having predicted its path). This takes place in a tiny fraction of a second, with almost no conscious effort, and almost never fails. So recreating human-esque vision in machines, as an example, is a set of interconnected problems each of which relies on the other.
The Solution — Deep Learning
BLUF: Deep Learning refers to a specific kind of Machine Learning technique — multi-layer Artificial Neural Networks (ANN) (other synonyms: multilayer perceptrons, deep neural nets, etc.) — which is very good at learning patterns and using that intel to classify or predict outputs given a set of inputs.
Demo:
Tinker with a Deep Learning framework (ANN) in your browser here.
Checkout Clarifai — a demo in object recognition.
ANN is actually a pretty old machine learning model that was inspired by the human brain (invented in 1957 by Frank Rosenblatt). A neural network is an interconnected set of nodes (each with an activation function) that are connected by edges, with differing weights, to solve problems like classification, regression, etc. For classification problems, for instance, each node will have a similar classifier but each node’s input is modified by different weights (edges) and biases. If you stack a lot of layers in a neural network (more than 3), that is suddenly considered deep learning. For simple pattern recognition problems, you could use simpler frameworks (Logistic regression or Support Vector Machines), but for anything with medium to high complexity deep learning will outperform other frameworks. Patterns are presented to the network via the ‘input layer’, which communicates to one or more ‘hidden layers’ where the actual processing is done via a system of weighted ‘connections’ as shown in this image to the right. ANNs are able to break down the bigger pattern into smaller patterns. Image recognition, for instance, is performed in small chunks to see if there’s a human face (starting from looking for simple things like vertical and horizontal edges for instance).

The Building Blocks (BB) of Deep Learning
There are three basic characteristics of any ANN : data, computational hardware and an algorithm.
BB#1 Data Scale (needed for accurate training)

The more data you let the ANN train on, the better the outcome is. To get a sense of scale, Google’s face recognition algorithm trained on about 260M images in 2015.
However for most real world problems, you probably need somewhere around 10k to 100k data points. If you don’t have a lot of data you could
Fine Tune: Take a strong pre-trained network that has trained on a large dataset (easy to find) and use it as an initial network for your problem. This was not true until a couple years ago, but now is possible given a much better ecosystem.
Augment Data: You can add random transforms (such as crops, mirrors or rotations) to artificially increase the amount of training data.
No matter what learning algorithm you use, performance gets better with more data.
BB#2 Computer Hardware (needed for quick iterations)
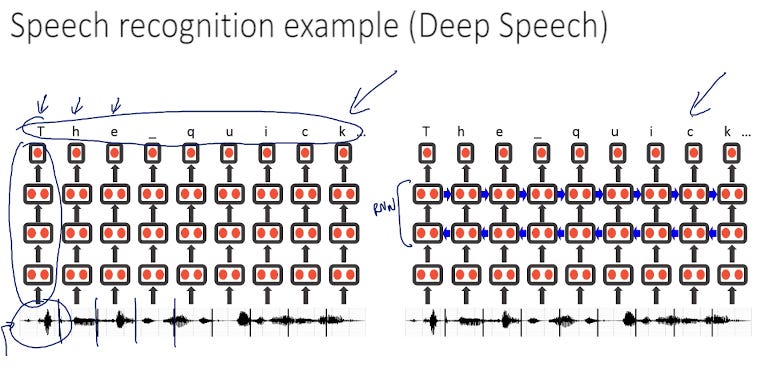
Value in AI is driven by empirical testing. Quick iteration speed on various algorithms helps researchers try out more ideas. E.g. How did scientists discover that Recurrent Neural Network (RNNs) is the best architecture for speech recognition? 7 years ago, Andrew Ng and team started out using an audio clip, cut it into steps, feed into a vanilla NN (simplified diagram below) to get the output transcript. This didn’t work and after some experiments they realized they needed to move to a Recurrent NN that led to the creation of Deep Speech
CPU → GPU → Cloud → HPC.
At the core of ANN algorithm is linear algebra. Linear algebra is inherently a parallelizable problem and hence parallelizable GPUs (such as those from NVIDIA) have become common hardware for training large scale NNs. Here’s a good primer on the linear algebra behind cost functions
With the rise of High Performance Computing (HPC) experiments that took weeks and months are now being done in days and hours. Bleeding edge of AI is moving to HPC, bringing down the iteration speed to days. Instead of testing dozens of ideas a year, we can now test hundreds of ideas a year.
BB#3 Algorithms for Feature Representation: Each node in each layer is a computational units. This means each node performs some computation (normally nonlinear like a sigmoidal function, hyperbolic tangent nonlinearity, or rectifier linear unit) given its inputs from the previous layer. The feature representation / loss-function that works best for a specific problem is a result of teams of 1000s of researchers spending dozens of years. Example — image from SIFT paper for computer vision that took 10 years to come up. Thankfully, this hard-work has now been abstracted out (for vision, audio and text). The growth here is very empirical, hence the need for better computing infra to move the research faster.
Unsupervised learning using unlabeled data.
Feature extraction
Unsupervised learning
Pattern recognition
Best algo — RBM (Restricted Boltzman Machine), auto-encoders
Text processing (RNTN Recurrent Neural Tensor Net (character level parsing))
Image (DBN Deep Belief Net, Convolutional Net)
Object (RNTN, Convolutional Net
Speech (Recurrent Net). Examples of NLP features: Stemming, Anaphora, Named entity recognition, Ontologies (WordNet)
General
General Classification. → RELU
Time series analysis → recurrent net.
So what’s the big hype?
BLUF: Since 2012, there has been a huge jump in accuracy of ML techniques (~74% → 84%), because they started using ANNs and realizing the giant leap provided by ANNs, the industry is investing resources (hardware, software, data, money) at an unprecedented rate.
DL became feasible only in recent years because of four broad advancements:
Large data sets image-sets given trillions of sensors everywhere. To build face recognition models that are as good, if not better then humans: FB used 4.4M to train in 2014 and Google used 260M images to train in 2015.
GPUs and HPC — at the heart of deep learning is Convolutional NN which does repeatedly similar computation, so you can push much of the logic to the hardware layer (in Silicon). So more and more specialized hardware is being built, though still in very exploratory state
Algorithmic improvements (Lots of potential detail here, skipping for the summary) are abundant given compounding from higher processing power, larger datasets and more investment into the area.
Capital investments, MnA activity is fueling the resources pouring in
Applications
Today, Deep Learning is the state if the art approach in almost every computer vision (ANNs are better than a human for face recognition, for instance), voice recognition (Siri, Alexa) and Natural Language Processing tasks. Application of Deep learning today is easy.
Step 1 Choose your weapon (package) -
Caffe/Digits (Matlab + Python)
TensorFlow (Python)
Torch 7
Theano/Keras/Lasagne (Python)
MatConvNet (Matlab)
Step 2: Get a GPU or use cloud resources (AWS, IBM Softlayer)
Today it’s used for (non-exhaustive list below, a much more comprehensive one here):
Machine vision — Image classification, Object recognition
Video recognition — Theft prevention and Self-driving cars
Speech recognition — Siri, Alexa
Text processing — fact extraction, machine translation, sentiment analysis (movie ratings), caption creation.
Healthcare — Earlier Cancer detection, Drug discovery based on chemical structure
Radiology — classifying malignant tumor versus benign tumor. Using MRI, FMRI, CT scans data
Finance — short and long term triggers to create alpha, portfolio allocation, etc.
Digital advertising — Segment users to make more relevant ad, Based on historical prices, optimal bidding
Fraud detection — credit card charges
Customer intel in marketing and sales — Upsell and cross-sell
Agriculture — predict and insure against problematic environment issues.
Play Games optimally (especially ones with large number of permutations) — AlphaGo
My take on the next frontiers / next big waves:
Generative Learning: Learning about learning, generative learning is the next step. Task: Not just answer the question, but make machines ask the right questions. That way you’re able to creating AI with some understanding of context (e.g. the Boston driverless Tesla versus the SF one). A lot of current AI is Task-driven work but the sense of General AI (understanding intention / purpose / communication / context) is not getting anywhere. We are very far from generative learning: we are able to do captioning and even QnA style work. But we need to get the algorithm to learn to explore to ask the right question.
Chip Design, ASIC and FPGAs : Generally speaking, the more function specific the hardware is (custom designed ASICs, FPGAs) the more efficient it is at that task. At the same time, however, it loses plasticity and cannot adapt to changing software demands. So the right hardware for Deep Learning, and other AI algorithms, has to have the ability to both specialize and morph. This would not be a general purpose computer, or an ASIC device, this would be a particular new type of neuromorphic hardware. Hardware, however, is only half of the problem, and the real game-changer I think will be a platform that is the right combination of software and hardware. This platform would allow you to code and run applications on neuromorphic hardware as easily as you would run a Python or C++ application.
Companies worth looking at:
Healthcare
Sano: Continuously monitor biomarkers in blood using sensors and software.
Enlitic / MetaMind / ZebraMedical: Vision systems for decision support (MRI/CT). Enlitic has developed deep learning networks that analyze medical imaging data such as x-rays and MRIs. Their networks increase diagnostic accuracy in less time and at reduced cost when compared to traditional diagnostic methods. Enlitic’s software also allows comparison of an individual patient’s radiological data with millions of other patients who received the same diagnosis in order to identify and track treatment outcomes for the most similar cases.
Deep Genomics / Atomwise: Learn, model and predict how genetic variation influence health/disease and how drugs can be repurposed for new conditions. Deep Genomics uses deep learning networks to predict how both natural and therapeutic genetic variation changes cellular process such as DNA-to-RNA transcription, gene splicing, and RNA polyadenylation. Applications include better understanding of diseases, disease mutations and genetic therapies. Spidex, their first product, provides “a comprehensive set of genetic variants and their predicted effects on human splicing across the entire genome. “
Flatiron Health: Common technology infrastructure for clinics and hospitals to process oncology data generated from research.
Google filed a patent covering an invention for drawing blood without a needle. This is a small step toward wearable sampling devices.
Enterprise Automation
Sigopt — SigOpt is the optimization platform that amplifies your research. SigOpt takes any research pipeline and tunes it, right in place. Our cloud-based ensemble of optimization algorithms is proven and seamless to deploy, and is used by globally recognized leaders within the insurance, credit card, algorithmic trading and consumer packaged goods industries.
Arimo — empowers companies with a new way to grow revenues and better understand their business. With innovative Distributed Deep Learning architectures, Arimo’s Behavioral AI solution allows companies to incorporate customer behaviors and digital assets into their business, marketing, and strategic decisions. Team includes executives who held held senior positions at Google, Yahoo, Amazon, SAP, Microsoft, and VMware. Arimo received $13M in a Series A raise from Andreessen Horowitz, Lightspeed Ventures, and Bloomberg Beta.
Ditto Labs has built a detection system that uses deep learning networks to identify company brands and logos in photos posted to social media. Their software also identifies the environment in which brands appear and whether a brand is accompanied by a smiling face in the photo. Clients can use Ditto to track brand presence at events or locations, compare brand performance with competitors, and target advertising campaigns.
Nervana provides a deep learning framework called neon that allows users to build their own use-case deep learning networks. They also provide a deep-learning cloud service where users can import and analyze their data using one of Nervana’s deep learning models or a model of their own design that uses neon. They suggest solutions in the areas of finance, energy and online services among others.
Databricks — Databricks is a company founded by the creators of Apache Spark, that aims to help clients with cloud-based big data processing using Spark. It brings DL techniques into enterprise customer’s application to make it faster, predictive and user-friendly.
Machine Vision, Speech recognition
Comma.AI (George) — Self-driving car add-ons.
Affectiva — MIT Media Lab spinoff that uses deep learning networks to identify emotions from video or still images. Their software runs on Microsoft Windows, Android and iOS and works with both desktop and mobile platforms. Applications include real-time analysis of emotional engagement with broadcast or digital content, video games that respond to the player’s emotions, and offline integration with a range of biosensors for use in research or commercial environments.
Gridspace uses deep learning networks to drive sophisticated speech recognition systems. Their networks begin with raw audio and build up to topic, keyword and speaker identification. Their Gridspace Memo software is designed to identify speakers, keywords, critical moments, and time-spent-talking, along with providing group take-aways from conference calls. Gridspace Sift provides similar information about customer service and contact calls.
Security
Deep Instinct is a cybersecurity company that uses deep learning networks to detect, predict and prevent advanced persistent threats in real time. Their software operates on all servers, operating systems and mobile devices. A program tailored to the customer’s security needs serves as the middleman between Deep Instinct’s deep learning network and the customer’s desktop and mobile platforms. The customer’s endpoints are protected whether or not they are logged into the company network.
Appendix
Some Glossary notes for common terms that one may come across while reading about Deep Learning
Gradient Descent — Gradient descent is a first-order iterative optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient (or of the approximate gradient) of the function at the current point.
Back Propagation — common method of training artificial neural networks used in conjunction with an optimization method such as gradient descent.
Convolutional Neural Network — Great summary here
Deep Belief Network — generative graphical model, or alternatively a type of deep neural network, composed of multiple layers of latent variables (“hidden units”), with connections between the layers but not between units within each layer.
Restricted Boltzmann Machine — a generative stochastic artificial neural network that can learn a probability distribution over its set of inputs. Stack together to create a DBN
Deep Reinforcement Learning — Generative Intelligence, Great summary here
Apprehending Great tools with simplicity.