
Why we invested in Baseten
Building the inference abstraction layer

Inference is compounding, not linear
“[Inference] is about to go up by a billion times.” Jensen Huang said it plainly on BG2, a perspective gaining traction across the industry. The implication is straightforward: as AI shifts from demos to default, the bottleneck moves from training to production inference.
Early AI products looked like single requests and single responses. The next generation looks like loops: retrieve, reason, call tools, rerank, synthesize, and often do it multiple times per user interaction. That structure multiplies inference events per task, and it raises the bar on latency, reliability, and cost.
At the same time, more of the AI stack is becoming “always on.” If a product’s core workflow depends on a model call, downtime and jitter are no longer acceptable. Teams need a platform that can meet production expectations while they stay focused on their differentiated product work.
The data backs this up. Google processed 9.7 trillion tokens in the month of April 2024. By April 2025, that number hit 480 trillion - a 50x increase in twelve months. By October 2025, it crossed 1.3 quadrillion per month. Another 3x in 3 months! And we’re still in the early innings.

Open weights expand the surface area
A second tailwind is the rapid improvement of open-weight models. As open models get more capable, more teams choose to run a portfolio of models: frontier APIs for certain tasks, open models for high volume workloads, and fine-tuned models for domain-specific performance. The world trends toward a multi-model future, not a one-model monoculture.
That choice creates a new kind of complexity. Running open models well requires expertise across runtimes, quantization, compilation, caching, hardware selection, and capacity management. Most application teams do not want to build an internal “GPU platform team” just to ship their product.
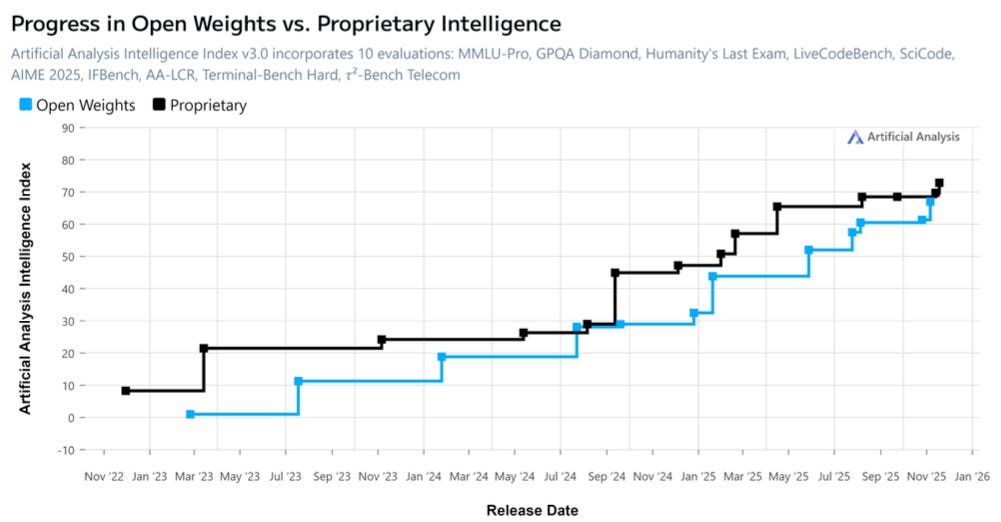
Source: Artificial Analysis (Dec 2025)
Baseten’s core value: abstraction
We view Baseten as doing for inference what Stripe did for payments: abstracting away the operational and engineering burden so product teams can move faster. Stripe made payments programmable by hiding the messy primitives behind a clean interface. Baseten does the same for model serving by abstracting deployment, scaling, routing, and performance tuning across models and environments.
There is also a Snowflake and Databricks parallel. The hyperscalers provide the raw infrastructure. The winning platforms make it simple to use, easy to scale, and predictable to operate. Baseten sits on top of cloud primitives and turns inference into a higher-level product.
Yes, a cloud provider could build more of this over time. We underwrite that reality. Our bet is that a focused platform can deliver the best mix of performance and total cost of ownership, with a product and support model designed specifically for production inference.
Baseten’s wedge is not just “GPUs as an API.” It is an inference stack and workflow that looks closer to a production system than a managed endpoint:
Performance engineering: systematic optimization work across runtimes and serving techniques that improves latency and throughput for real workloads.
Multi-cloud capacity management: the ability to source and manage capacity across environments, and to design for resiliency when regions or providers have issues.
Deployment flexibility: options that fit how teams actually operate, including dedicated deployments and hybrid approaches for stricter security requirements.
Developer experience: a clean interface that helps teams ship, debug, and iterate without turning infrastructure into their full-time job.
Deep customer partnership: an “own the outcome” posture that shows up in how quickly issues get resolved and how much help customers get in production. This posture comes from the team. Co-founders Tuhin Srivastava and Amir built Baseten around customer co-design, and institutionalized it with a forward deployed engineering model led by Joey Zwicker, where engineers embed with customers and own production outcomes.
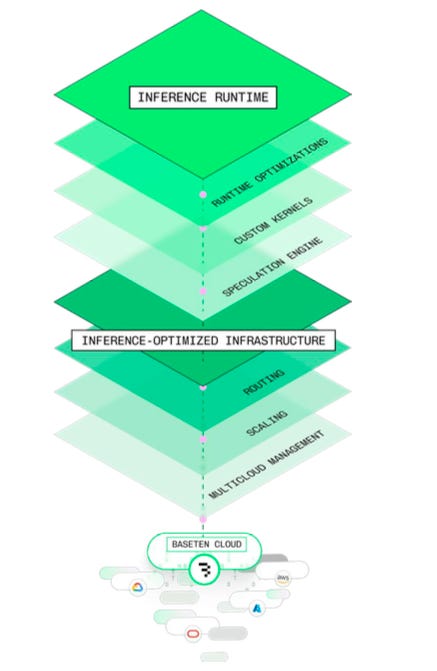
Source: Baseten
Baseten = an index on AI agents
In the same spirit that Stripe is an index of the internet economy, Baseten is an index on the AI economy. Baseten scales with the success of the application layer. When an app grows, inference volume grows with it. You get exposure to the compounding of AI-native usage, not just seat expansion.
Baseten’s publicly disclosed customers include: Cursor, Notion, OpenEvidence, Abridge, Clay, World Labs, Gamma, Writer, Bland AI, Descript, Ambience, Hex, Wispr Flow, Latent Health, etc. some of the fastest growing businesses! This helps to explain the explosive momentum : Baseten’s revenue 10x-ed in 2025.

Source: Baseten
Customer proof: OpenEvidence
A good way to understand Baseten is through the teams that ship high-stakes products. OpenEvidence serves clinicians who need fast, trustworthy information at the point of care. As OpenEvidence scaled, running inference in-house consumed more time and attention, pulling focus away from the product. They moved to Baseten to offload infrastructure work and improve performance, while keeping their team concentrated on building tools for physicians.
The story is common: customers start with in-house infrastructure or generic cloud building blocks, then hit a wall as production requirements harden. Baseten is designed to be the point where teams can scale inference without becoming an infrastructure company.
The thesis
We believe inference is becoming the dominant workload of AI. Open-weight models and multi-model architectures are expanding what gets deployed. Baseten is building the abstraction layer that makes production inference simple to adopt, efficient to run, and reliable at scale.
We invested because we believe Baseten can become a foundational platform in the AI application economy: the infrastructure choice for teams that care deeply about performance, reliability, and shipping.
Disclaimers: https://www.altimeter.com/terms
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update the information or analysis contained herein in the future.
What helps inference optimization platforms like Baseten win against hyperscalers in the long run?
How will they continue to win against hyperscalers esp on cost since AWS/GCP/Azure are full stack (compute + infra + customer distribution)?
Brilliant. Multimodality is key, but the ethical implications?