
Why we are doubling down on Baseten

We backed Baseten in Q4 2025, and I wrote up the thesis then. Six months on, it has only gotten more obvious to us, and faster. By the end of Q1, Baseten had already surpassed the full-year CY26 forecast we had underwritten. The updated thesis is:
We believe inference will be
one ofthe largest marketin AIPost-trained open source models deliver the best combination of capability, cost and control
Baseten provides the entire model supply chain to harness open source. Train, deploy, and serve models all on the same platform
Baseten = index on AI economy
Inference will be the largest market
Some truths are so large that they need to be repeated. If you wrote in 2003 that the internet was going to be big, the right move was not to retire the point in 2004. It was to keep saying it, because the magnitude was still underappreciated.
We feel similarly about inference. We think it will become the largest market in the world by the end of this decade. Not the largest software market… THE largest market. Why? It is a fundamental primitive of the AI economy. Training creates the model. Inference serves the product.
The simplest analogy is an electricity meter. Every time an AI product does useful work, the meter runs. The product may look like software to the user, but underneath it is a continuous stream of model calls. More users, longer prompts, larger context windows, more reasoning steps, more tools, more agents, more retries, more evals, more personalization: all of it turns into more inference.
Early AI products were mostly single-turn. Ask a question, get an answer. The next generation is not single-turn. It is loops: retrieve, reason, call tools, inspect results, rerank, synthesize, verify, and often repeat. One user action can generate hundreds or thousands of inference events.
That is why I keep coming back to the same line: inference will be the largest market.
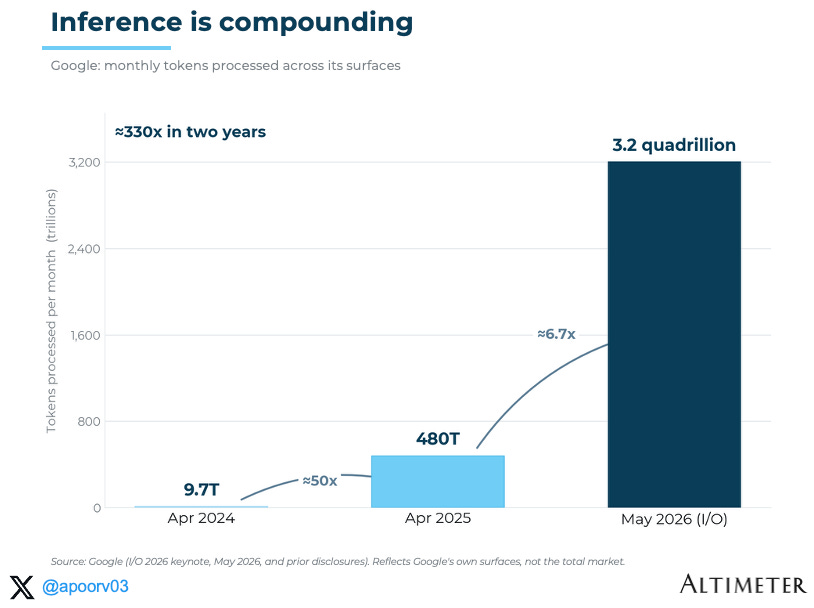
Google’s public token data gives a useful directional signal. Two years ago, Google said it was processing 9.7 trillion tokens per month across its surfaces. Last year that became roughly 480 trillion. At I/O 2026, Google said that number had grown to more than 3.2 quadrillion tokens per month. Caveat: this is Google’s own stack and Google’s own surfaces, not the whole market. But it’s indicative of the broader point: inference is compounding at an extraordinary pace.
Post-trained open source models deliver best combination of capability, cost and control
A lot of ink is spilled on “open versus closed” as a religious debate. Closed frontier models are phenomenal. They are often the right choice for the most intelligent tasks, the hardest reasoning tasks, for model-as-a-service convenience, and for new capability discovery.
But the practical question for AI-native companies is different: what is the best model architecture for this workflow, at this quality bar, at this latency, at this cost, with this security posture, and this degree of control? A post-trained open source model can be better for specific workflows. Cheaper. Faster. It can run in the customer’s environment. It can be shaped by private evals, proprietary traces, domain-specific reinforcement learning, and the application harness around it.
Two factors are tipping the scales in favor of post-trained open source models: 1) exponential growth in token volumes (more capability → more utility → more usage) and 2) ownership (this is the most strategic one). Companies are realizing their models are becoming load-bearing, and they do not want their core intelligence to be something they rent. Satya Nadella described it best:

“A company should be able to switch out a “generalist” model without losing the “company veteran” expertise built into their learning system … Companies need to turn their workflows, domain knowledge, and accumulated judgment into AI systems that improve with each use … This loop becomes the new IP of the firm. I think of it as a hill climbing machine. And unlike most assets, it compounds.”
This shifts the paradigm from simply picking the best model to building a “learning loop” where human capital and token capital compound. The durable IP is now the “learning loop”: private data, private evals, workflow traces, domain feedback, reinforcement environments, product context, and model behavior that improves with usage.
That is the emerging pattern among the AI natives we surveyed: frontier models for the hardest general intelligence and post-trained open source for high-volume and specialized workloads. The latter allows AI natives to own their intelligence and compound their most valuable asset.
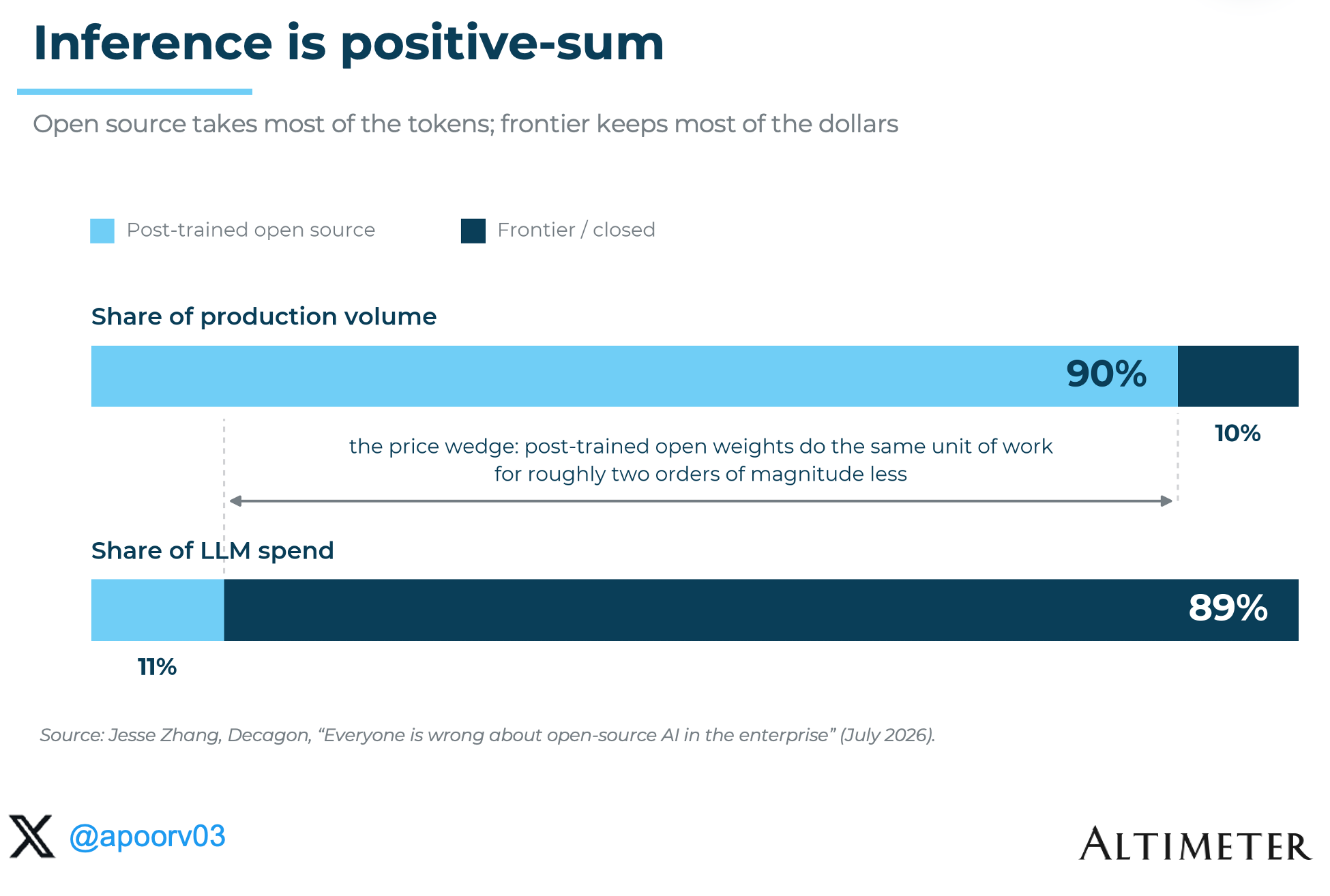
Jesse Zhang at Decagon offers a useful way to think about the split. Decagon already runs ~90% of workloads on open source, while open source represents 11% of enterprise LLM spend today. Those are different denominators, but they point to a positive-sum market: open models can absorb enormous volumes of mature, specialized work at much lower unit cost, while frontier models retain the newest, hardest and highest-spend tasks. As workflows mature, open source should take more production volume and a growing share of spend, while frontier models keep pushing capability forward and creating the next wave of demand.
Baseten’s model supply chain in practice: Harvey case study
Harvey is a useful public example because legal work is high-stakes, highly-skilled and deeply case-specific.
Harvey describes its model strategy: building a legal foundation model series inspired by Cursor’s Composer, with the goal of serving frontier intelligence across the product at an affordable price and strong security posture, while also creating the foundation for law firms to build specialized models and own their own intelligence.
That is the whole thesis in one customer pattern. Many specialized models, serving many specialized workflows, inside many specialized products.
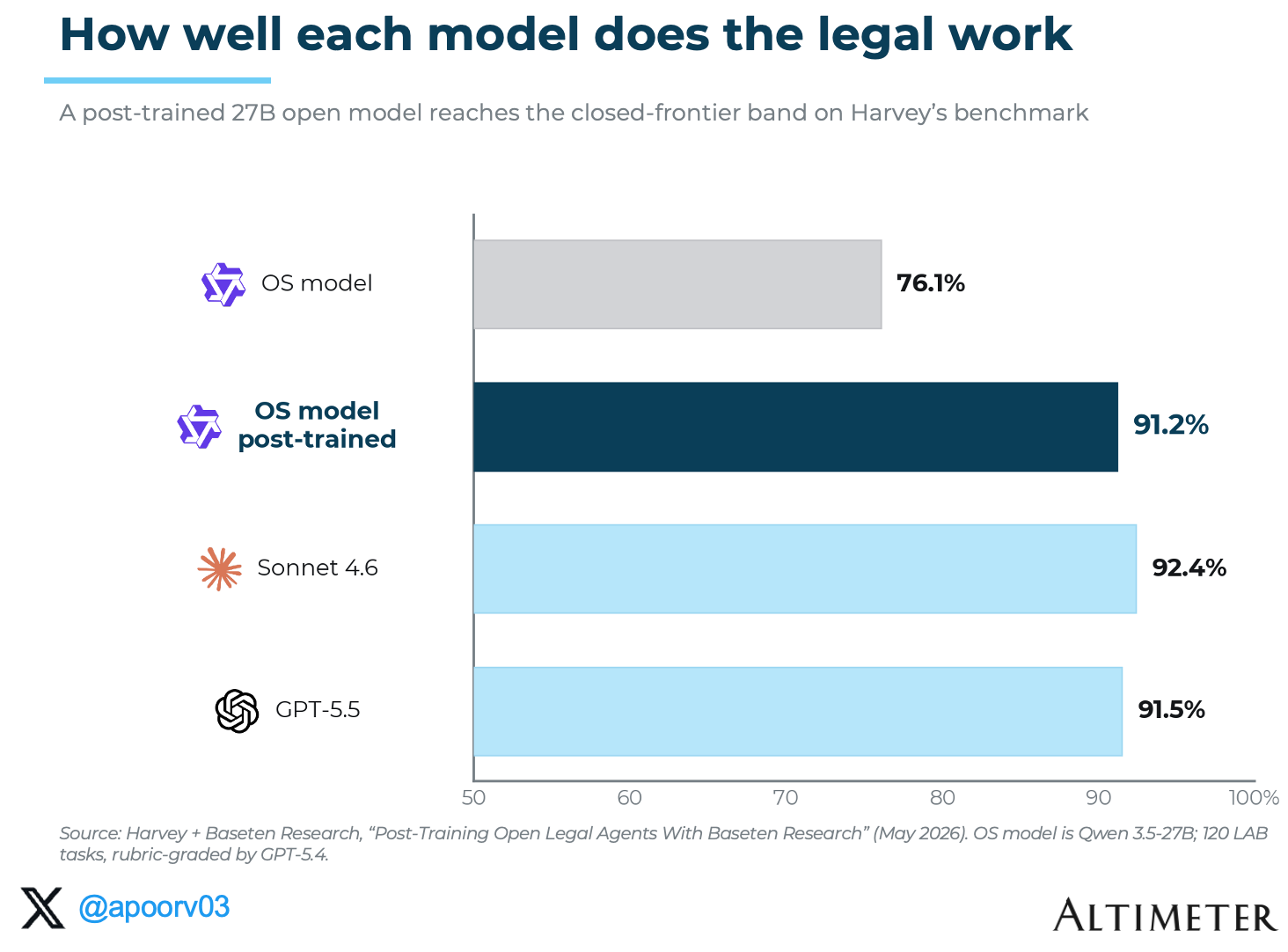
They built a model system around the actual work. In legal, the work often spans months, many documents, many people, many judgments, and many intermediate steps. Harvey’s agentic system needs to be able to read, reason, use tools, ask for help, preserve context, and improve on the tasks lawyers actually perform. Harvey’s research with Baseten is especially interesting because it shows how post-training and application harnesses come together. They used legal-agent benchmarks, domain-specific tasks, and Baseten Research to post-train an open source model into the closed-source frontier band on legal work.
The chart below from Harvey shows the core point: with the right post-training and application harness, a much smaller open source model can move into the frontier band on a domain-specific task. The goal is not to beat every frontier model on every benchmark. The goal is to deliver frontier-quality performance on the workflow that matters, inside a cost, latency, and control envelope that works in production. Harvey notes that frontier models run about $50 per task with roughly 20 minutes of latency. Their work with Baseten shows a path to comparable domain-specific quality at a much more practical cost and latency profile.
This is the pattern we first saw in AI-native companies: as model usage becomes load-bearing, they care more about the same trifecta of capability, cost, and control. That pattern is now moving into the enterprise. As larger companies shift from experiments to production, they want what the AI natives wanted, to own their intelligence and run it reliably. Enterprise is an increasing area of focus for Baseten, and it widens the market well beyond the AI-native core.
What this means for Baseten
In January, I called Baseten the “Stripe for inference”, and I still like the analogy. Stripe made payments programmable, abstracting away messy financial infrastructure so builders could focus on their product. Baseten does the same for inference: deployment, autoscaling, routing, observability, runtime optimization, capacity, security, and production support.
The offering is evolving. AI natives won’t run on one model. They will run on millions of model-powered workflows and each workflow may be best delivered by a different model. So what’s needed now is the full model supply chain: bring any model, post-train it on private data and evals, deploy and autoscale it across hardware and clouds, route and observe it, then feed production traces back into the next version. That loop is what AI-native companies need, and almost none of them want to build it themselves. They do not want a 100-person GPU platform team negotiating quota, debugging kernels, and stitching together five vendors. They want to build their product, and Baseten lets them.
Updated July 28, 2026 with additional data from Decagon on open-source volume and spend.
Disclaimers: https://www.altimeter.com/terms
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update the information or analysis contained herein in the future.